- Industry: Aviation
- GitHub URL: https://github.com/PoornimaKanasen/British_Airways_Virtual_Internship
Objective
To learn how to scrape customer review data and build predictive models.
Completed tasks
- • Project Understanding
- • Web Scrapping
- • Data Exploration, Model Development and Interpretation
- • Data Visualization and Storytelling
- • Build predictive models
Analysis
The following steps were carried out throughout the data preprocessing and cleaning phase:
Data Cleaning:
- • Removing ✅ Verified Review | from all the reviews
- • Changing all the reviews into lowercase
- • Apostrophe look up
- • Short words
- • Emoticons
- • Replacing numbers and special characters with space
- • Removing words whom length is 1
- • Spelling Correction - With TextBlob Library
Data preprocessing:
- • Tokenization
- • Enrichment - POS Tagging
- • Stopwords removal
- • Stemming
- • Lemmatizing
Tools used
Python, BeautifulSoup, Pandas, Numpy, Matplotlib, Seaborn, Sklearn
Insights
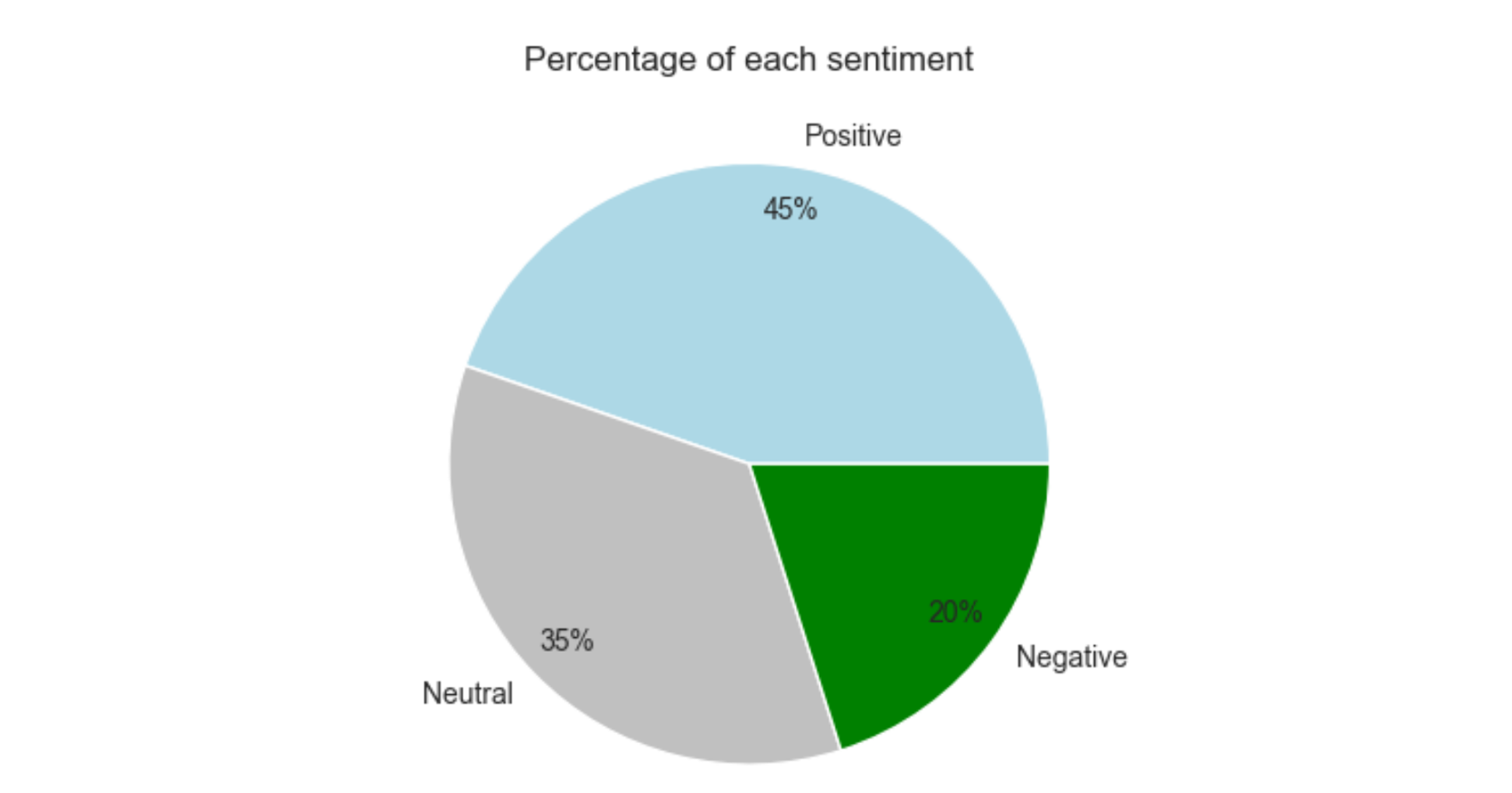
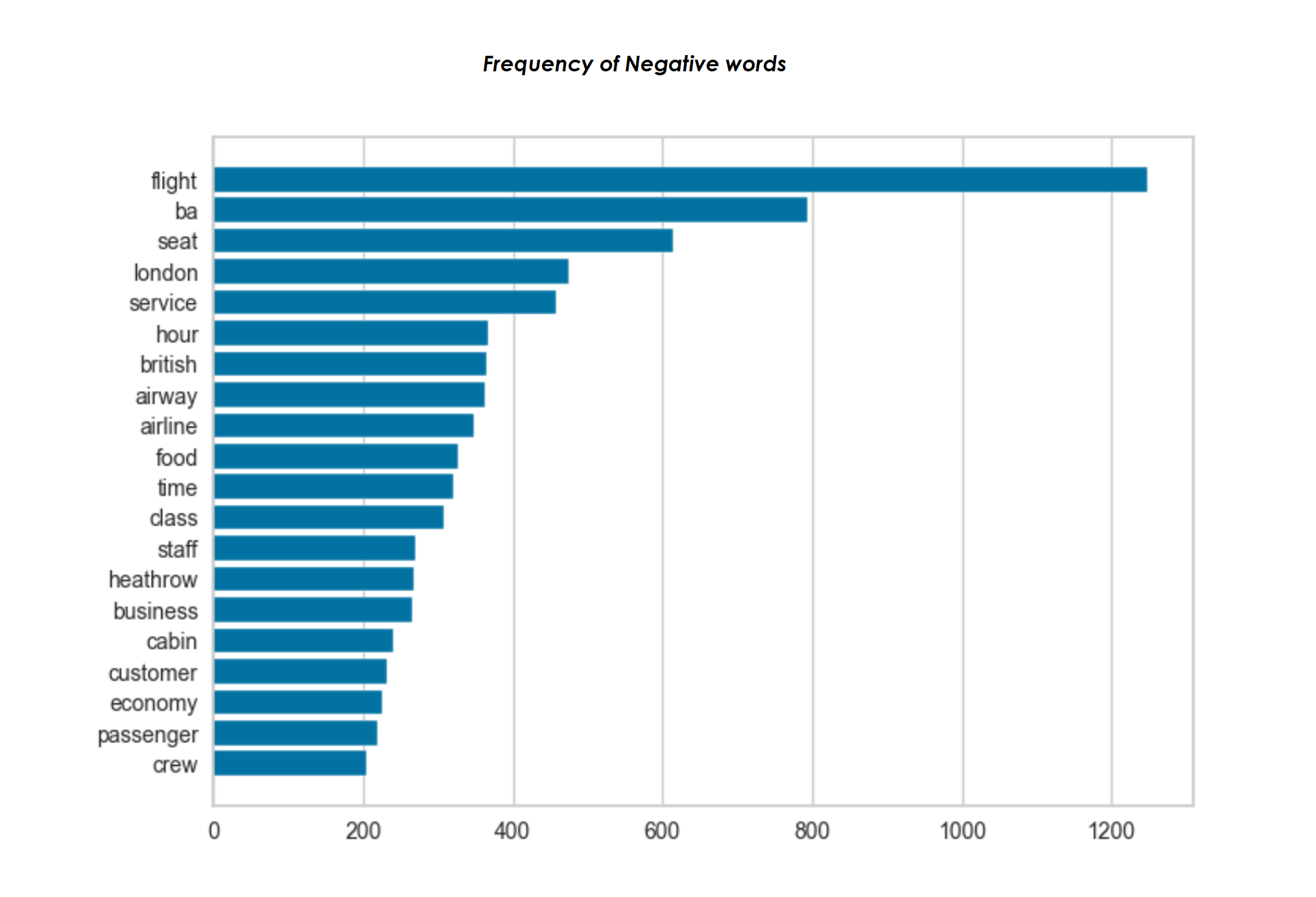
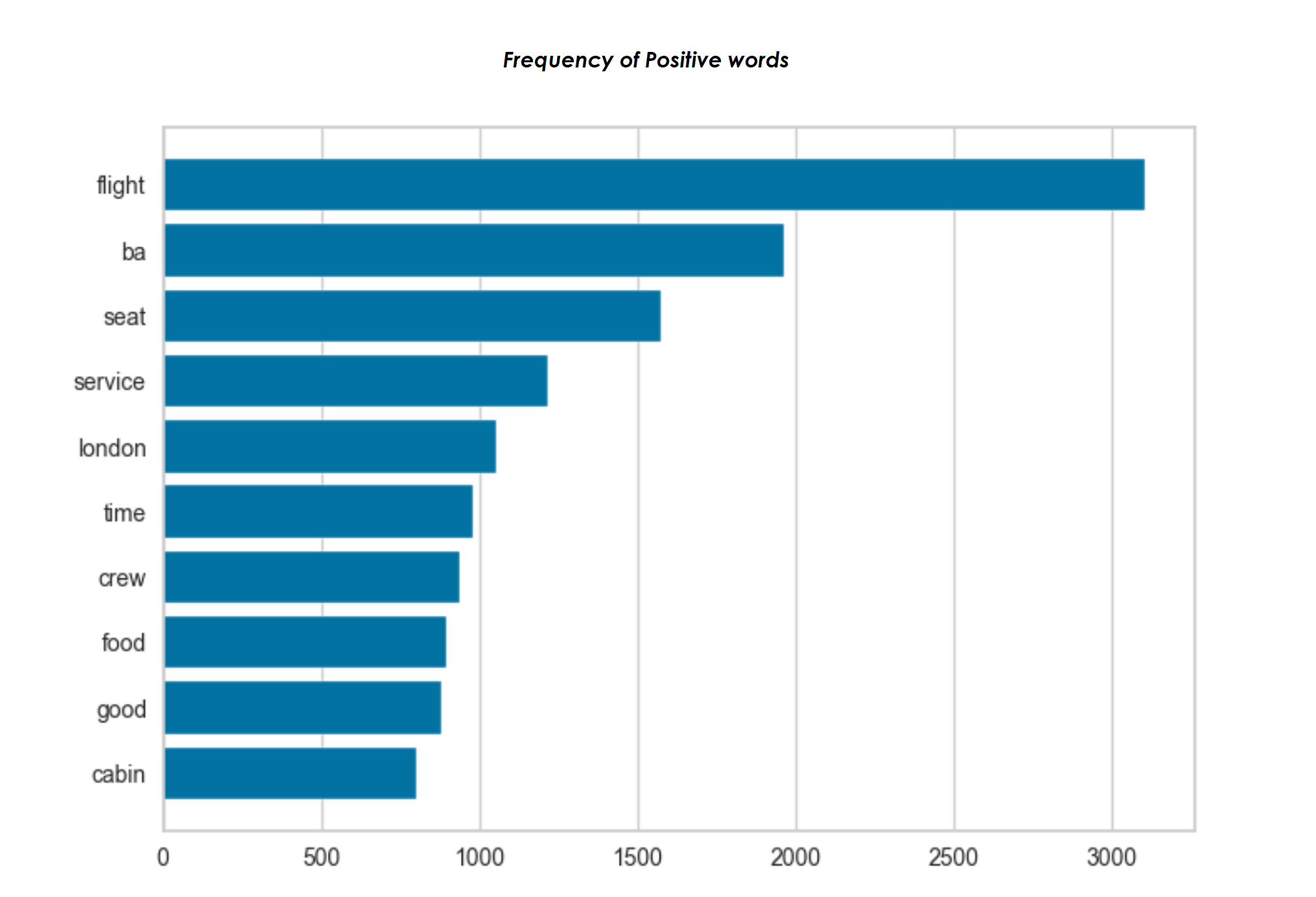
- • From our sentiment analysis with TextBlob, we have segregated the intensity of the comment into three categories which are negative, neutral and positive.
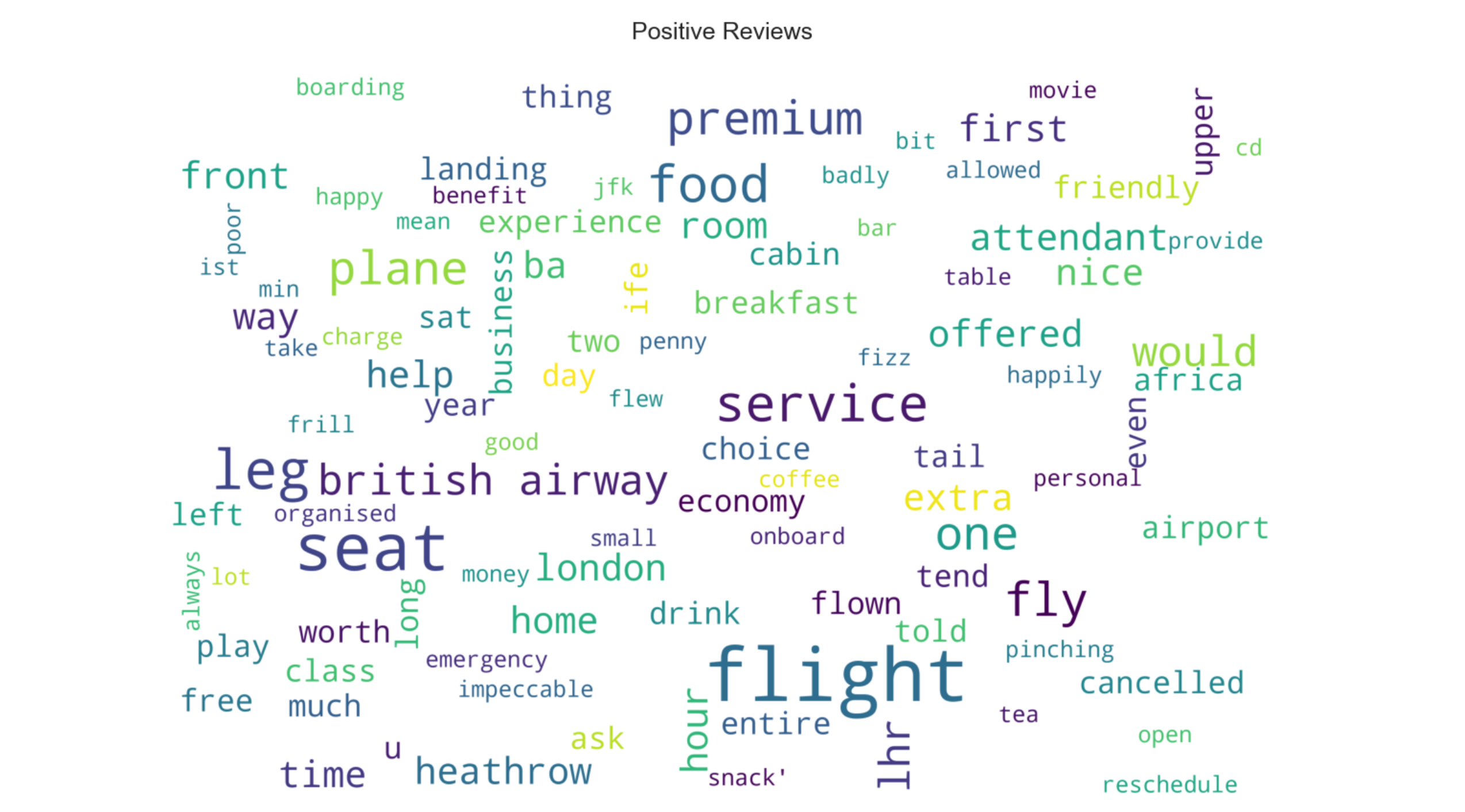
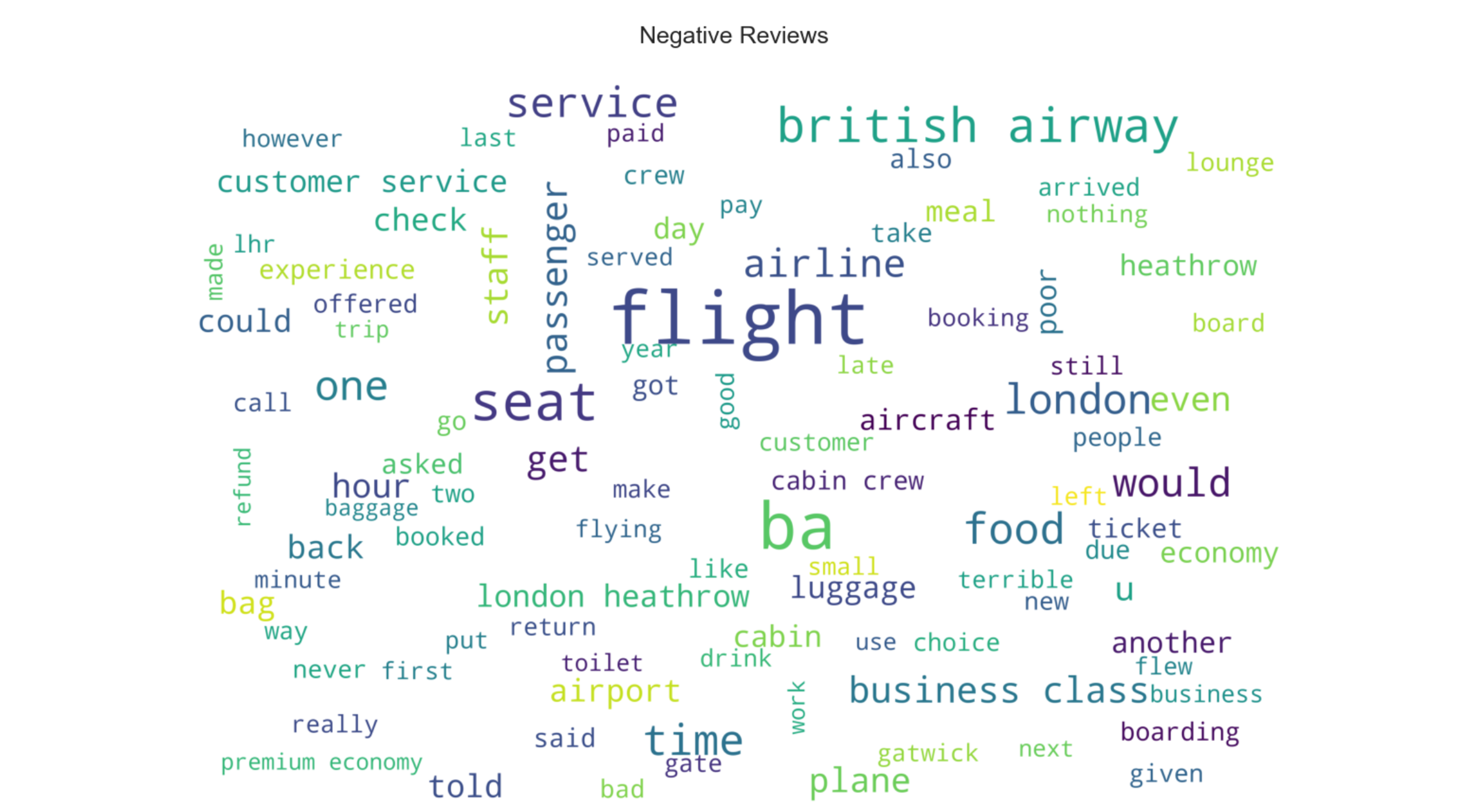
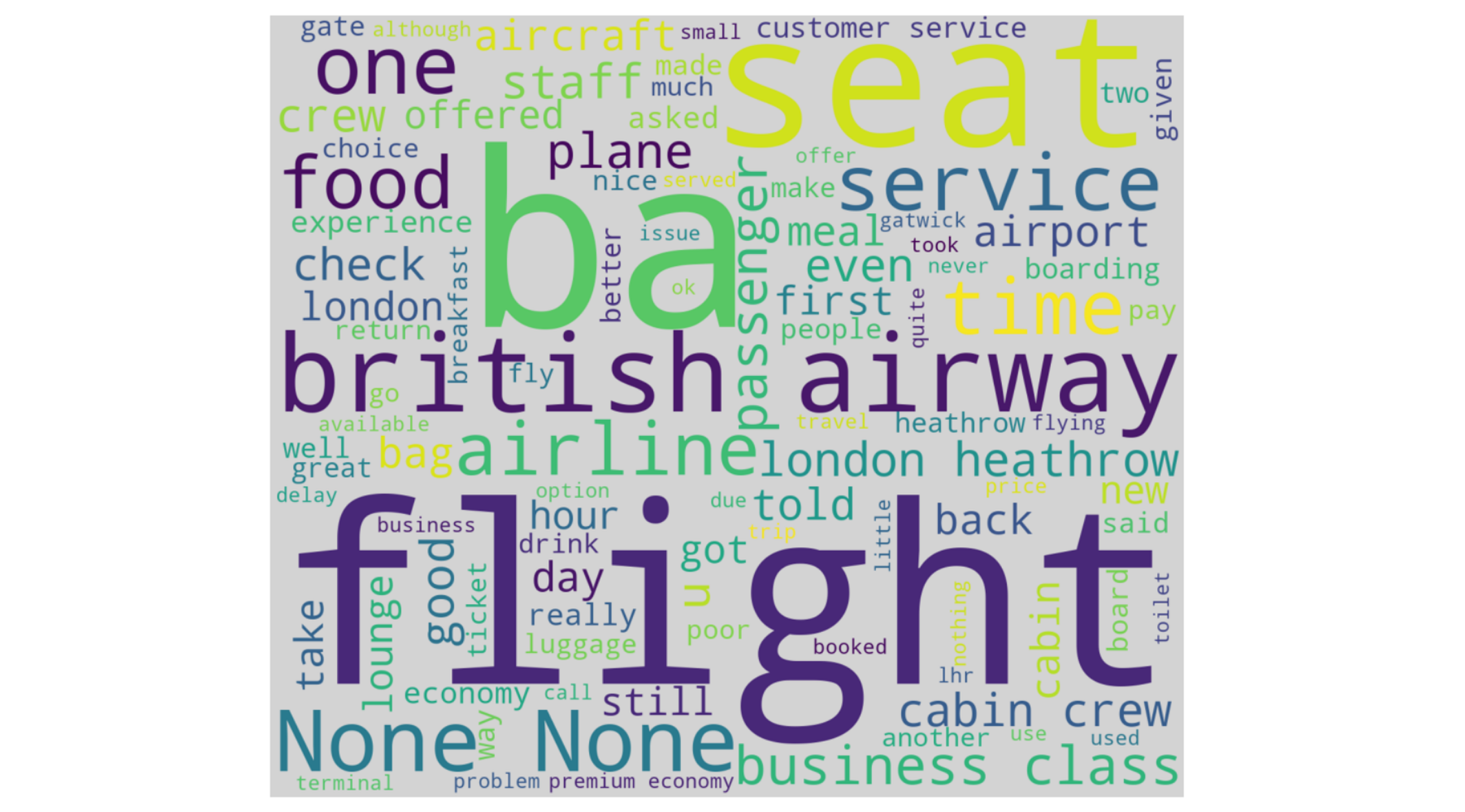
- • The wordclouds are an easier way to digest large amount of data. Most frequently used words are displayed in a larger font size and the less frequent words are displayed in smaller font sizes. Both the positive and negative wordclouds have some similarities. Positive Wordcloud shows words like flight, seat and legroom while the negative shows words like flight, seat, poor, bad and so on.
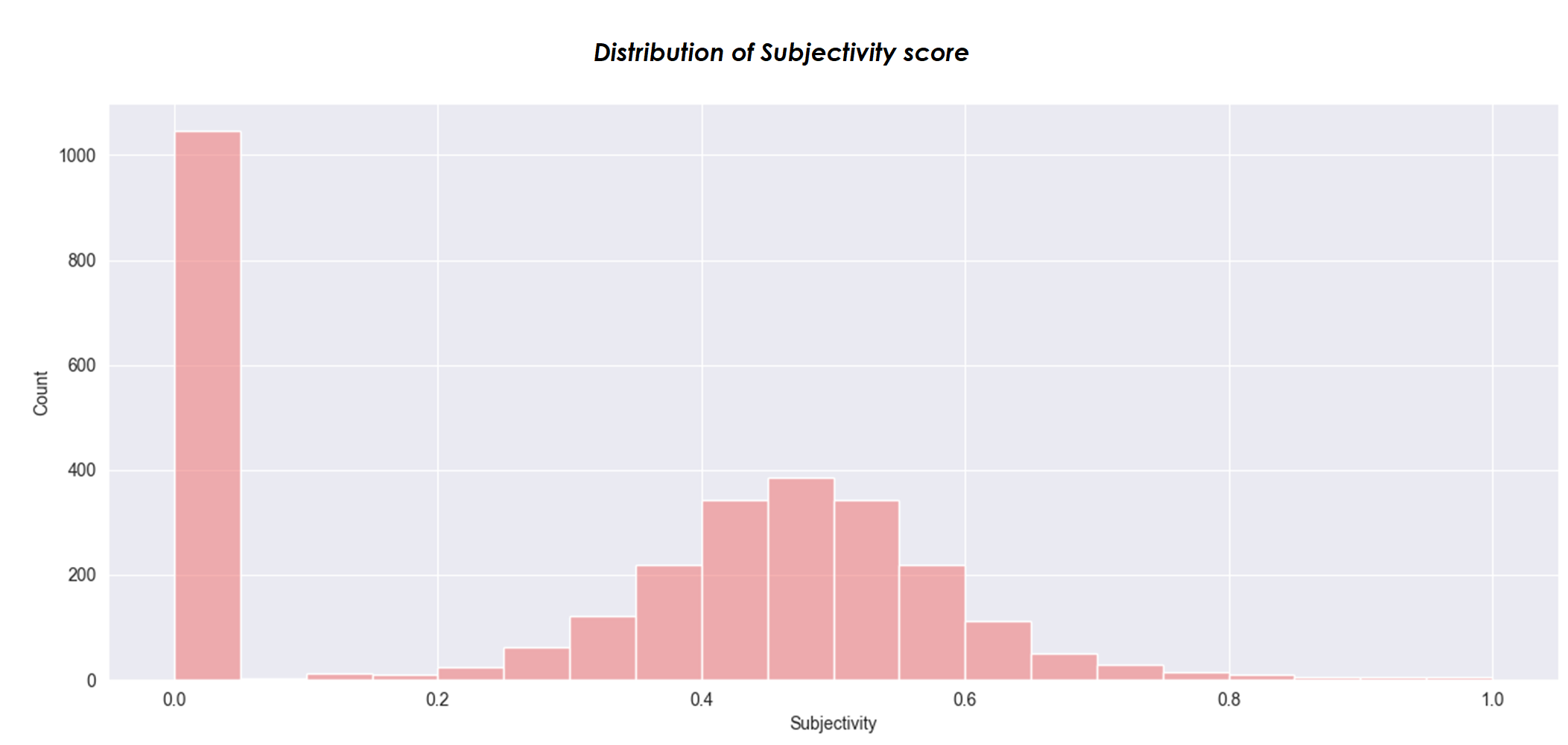
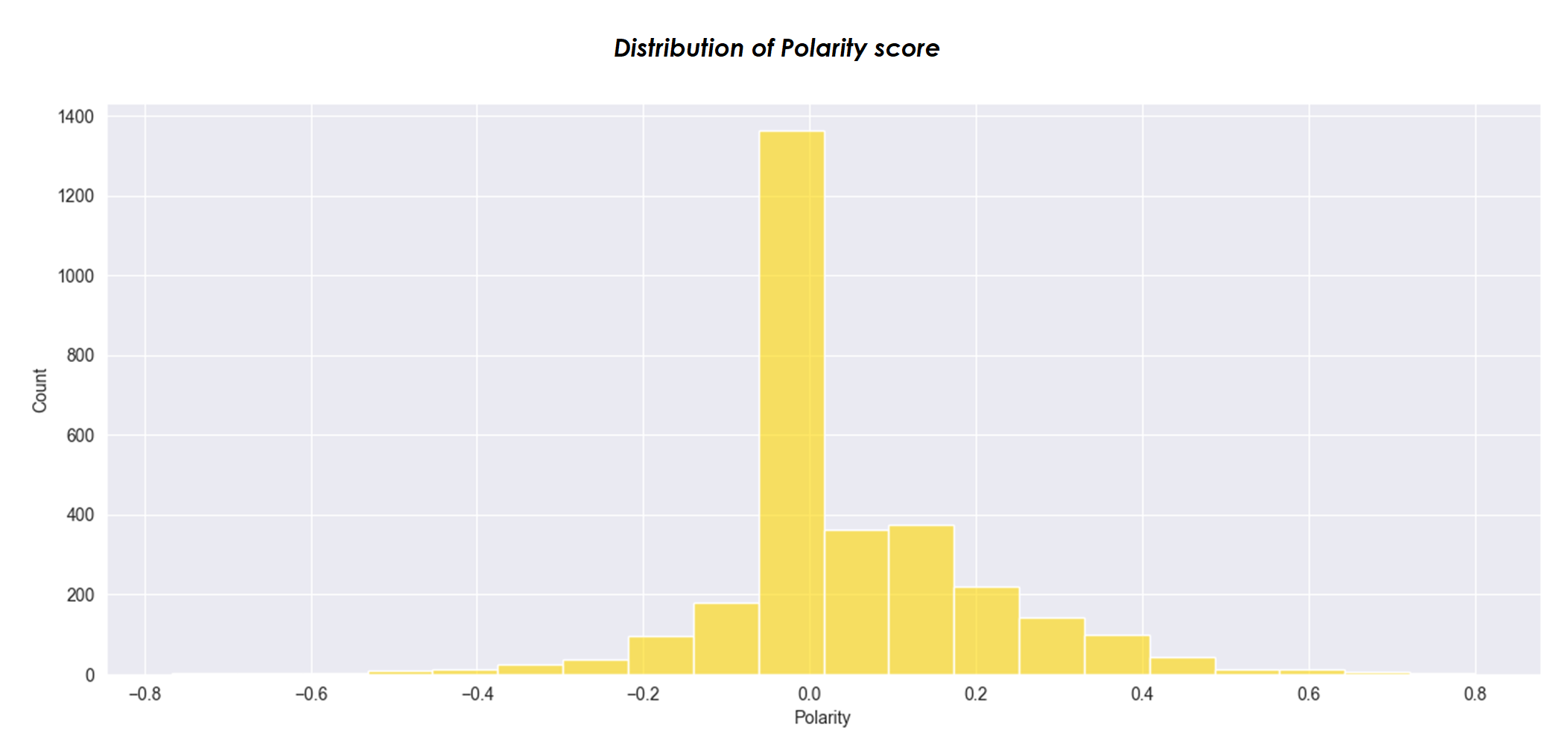
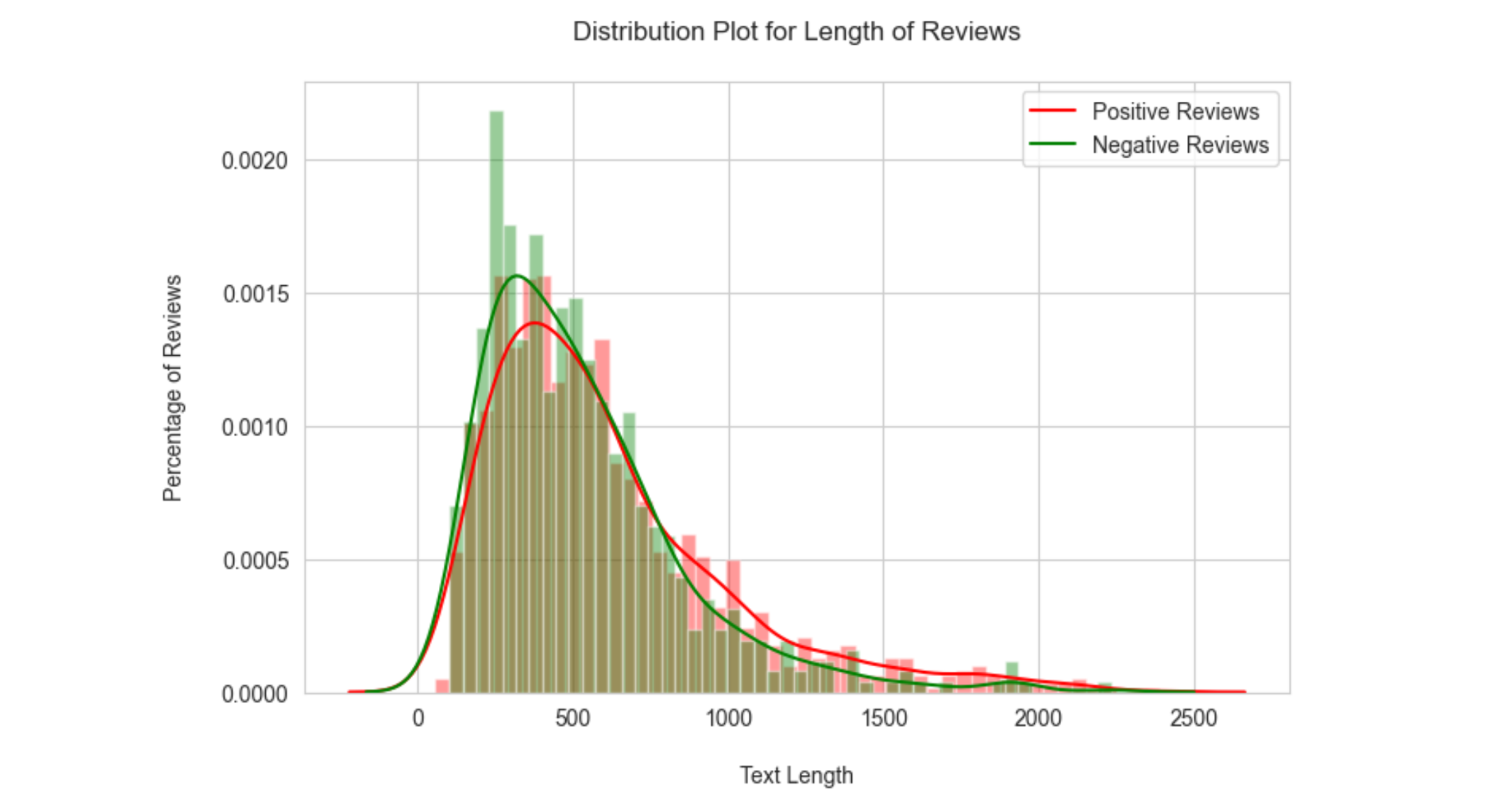
Visuals from Python-Jupyter Notebook-Pandas-Matplotlib-Seaborn